
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬
- 자료구조
- 스프링 컨테이너
- python list method
- AWS SAA-C03 합격후기
- getreference
- Spring
- 클래스 로더 계층
- 자바
- 파이썬 문자열 메서드
- 2026 AWS SAA-C03
- 스프링
- 플랫폼 클래스 로더
- java
- 컴포넌트 스캔
- 파이썬 리스트 메서드
- 어플리케이션 클래스 로더
- dfs
- stop the world
- 알고리즘
- 백준
- python
- aws saa-c03
- 심볼릭 레퍼런스
- 코딩테스트
- 딕셔너리
- 부트스트랩 클래스 로더
- 객체지향
- BFS
- 다이렉트 레퍼런스
- Today
- Total
클라우드 낚시꾼
[백준] 1012번 유기농 배추 - BFS 풀이(Python3) 본문

제한 조건과 설계

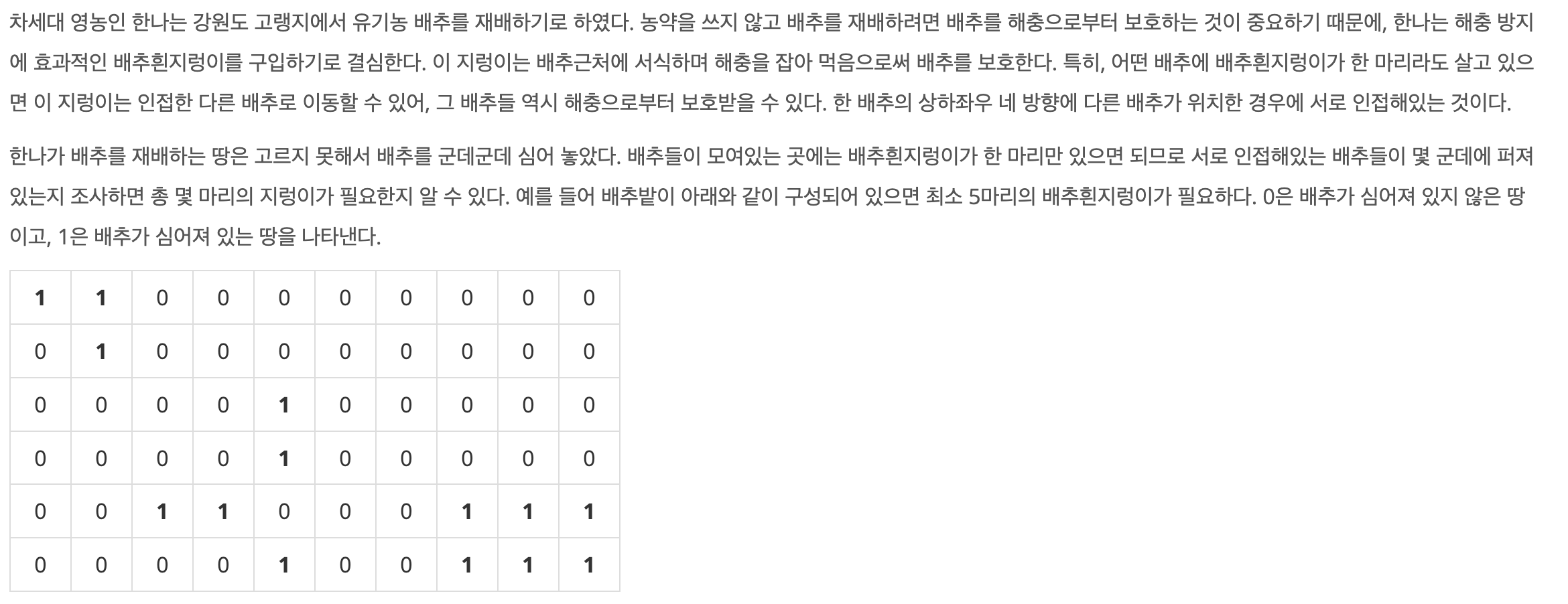
- 어떤 배추에 배추흰지렁이가 한 마리라도 살고 있으면 이 지렁이는 인접한 다른 배추로 이동할 있어, 그 배추들 역시 해충으로부터 보호가 가능하다.
- 1은 배추가 심어진 땅, 0은 배추가 없는 땅이다.
- 배추를 심은 배추밭의 가로길이 M(1 ≤ M ≤ 50)과 세로길이 N(1 ≤ N ≤ 50), 그리고 배추가 심어져 있는 위치의 개수 K(1 ≤ K ≤ 2500)이 주어진다.
- 그래프 탐색 문제이다.
- DFS로 탐색하기에는 그래프 크기가 2500이므로 RecursionError가 뜰 수도 있을 거 같아 BFS가 좋아 보인다.
자연어 알고리즘과 코드
1. 데이터를 입력 받는다
2. 배추 지점은 cabbage_locations에 저장한다.
3. 각 배추 지점을 시작 지점으로 BFS 탐색을 한다.
- BFS 탐색 전, 배추 지점이 1 -> 그 지점을 시작 지점으로 BFS 탐색을 시도하고 cnt(count)를 + 1 한다.
- BFS 탐색 전, 배추 지점이 0 -> 탐색하지 않고 다음 지점으로 넘어간다. (이미 탐색 되었기 때문)
4. BFS 탐색 알고리즘
- queue에 시작 지점을 넣는다.
- queue의 front를 dequeue 한다.
- dqueue 된 지점에서 상,하,좌,우로 움직인다.
- 0이면 (배추가 없는 땅) 또는 범위 밖 -> 무시하고 다른 방향으로 이동(continue)
- 1이면 (배추가 있는 땅) -> 그 지점을 queue에 enqueue하고 방문 처리(0)한다.
- 위 과정을 queue가 빌 때까지 반복한다.
5. cnt(필요한 최소의 배추흰지렁이 마리 수)을 출력한다.
import sys
from collections import deque
input = sys.stdin.readline
def bfs (start_x, start_y):
queue = deque()
queue.append((start_x,start_y))
graph[start_y][start_x] = 0
while queue:
x,y = queue.popleft()
for i in range(4):
ny,nx = y + dy[i], x + dx[i]
if nx < 0 or ny < 0 or nx >= m or ny >= n:
continue
if graph[ny][nx] == 0:
continue
queue.append((nx,ny))
graph[ny][nx] = 0
ans = [ ]
dy = [-1,1,0,0]
dx = [0,0,-1,1]
for i in range(int(input())):
m,n,k = map(int, input().split())
graph = [[0] * m for _ in range(n)]
cabbage_locations = []
cnt = 0
for a in range(k):
x,y = map(int, input().split())
graph[y][x] = 1
cabbage_locations.append((x,y))
for (x,y) in cabbage_locations:
if graph[y][x] == 1:
bfs(x,y)
cnt += 1
print(cnt)
망했던 이유 0: 이제까지 풀어 본 문제와 다른 입력
처음 이 문제를 풀때, test case가 요구되기에 graph 여러 개를 한 리스트에 모두 저장한 다음 graph 하나 하나를 문제로 가지와서 탐색을 할라 했는데 이미 graph가 2차원 리스트이여서 3차원 리스트가 발생하는 문제가 발견됬다. test case가 요구되는 graph 문제처럼 여러 graph를 다룰 때는 for문을 test case 만큼 실행하여 graph를 초기화하여 사용하면 된다.
망했던 이유 1: 가로, 세로 혼동
문제는 2차원 좌표평면 상의 좌표인 X, Y를 주지만, 우리는 그래프를 2차원 배열(행렬)로 다루어야 한다.
초반에 graph[x][y]로 혼동해서 계속 삽질을 했다. 2차원 배열이기 때문에 graph[y][x](graph[행][열]) 형태가 맞다.
망했던 이유 2: 얕은 복사를 간과했다.

그래프를 생성하는 코드인데, 여기서 처음에 row = [0] * m 하여 graph = [row for _ in range(n)]를 하였다. 나름 가독성을 위해 만든 코드인데 저렇게 되면 row라는 같은 참조 주소를 가진 참조 변수가 10개가 graph의 행을 구성하게 되어 한 행을 수정하면 다른 행에도 영향을 미치게 되는 문제가 발생된다.
망했던 이유 3: DFS 방문 처리를 간과했다.

처음에는 for 안에서 방문 처리하지 않고 for 밖에서 queue.popleft 한 순간 어든 x, y를 이용해서 그 다음 라인에 x,y를 방문 처리를 했다. 이렇게 하면 문제의 답은 맞으나 시간 초과, 메모리 초과 에러가 발생한다. 그 이유는 queue에 append 하자마자 그 지점을 방문 처리 하지 않았기 때문이다. queue에 넣자 마자 방문 처리 하면, 그 지점은 다시 방문할 수 없을 거라고 생각했으나 이는 완전 잘못된 생각이다.
이미 queue에 들어 왔다는 것만으로도 무조건 방문될 운명이다.
세 줄 요약
1. BFS에서 방문 처리를 안 해서 중복 되는 지점이 Queue에 들어가면 메모리 초과, 시간 초과가 발생한다.
2. BFS의 Queue에 append 되었다. = 그 지점은 방문될 운명이기에 방문 처리를 꼭 해야 한다.
3. 입력이 2차원 좌표평명 기준으로 x,y로 들어와도 우리는 2차원 리스트로 그래프를 다루기에 graph[행=y][열=x]로 다루어야 한다.
'CodingTest > 문제풀이' 카테고리의 다른 글
| [백준] 11724번 연결 요소의 개수 - DFS(stack, 재귀함수) (Python3) (0) | 2023.12.27 |
|---|---|
| [백준] 4963번 섬의 개수 - BFS 풀이 (Python3) (2) | 2023.12.27 |
| [백준] 16956번 늑대와 양 - Python3 (애드 혹 문제, 이 문제가 정말 BFS 문제 일까?) (1) | 2023.12.24 |
| [백준] 2667번 단지번호붙이기 DFS - Python3 (1) | 2023.12.21 |
| [백준] 2178번 미로 탐색 Python3 - BFS (0) | 2023.12.21 |



